When and How to Fine-Tune LLMs
Fine-tuning allows you to adapt a pre-trained language model to your specific domain or task. But it's not always the right choice. This guide helps you decide when to fine-tune and how to do it effectively.
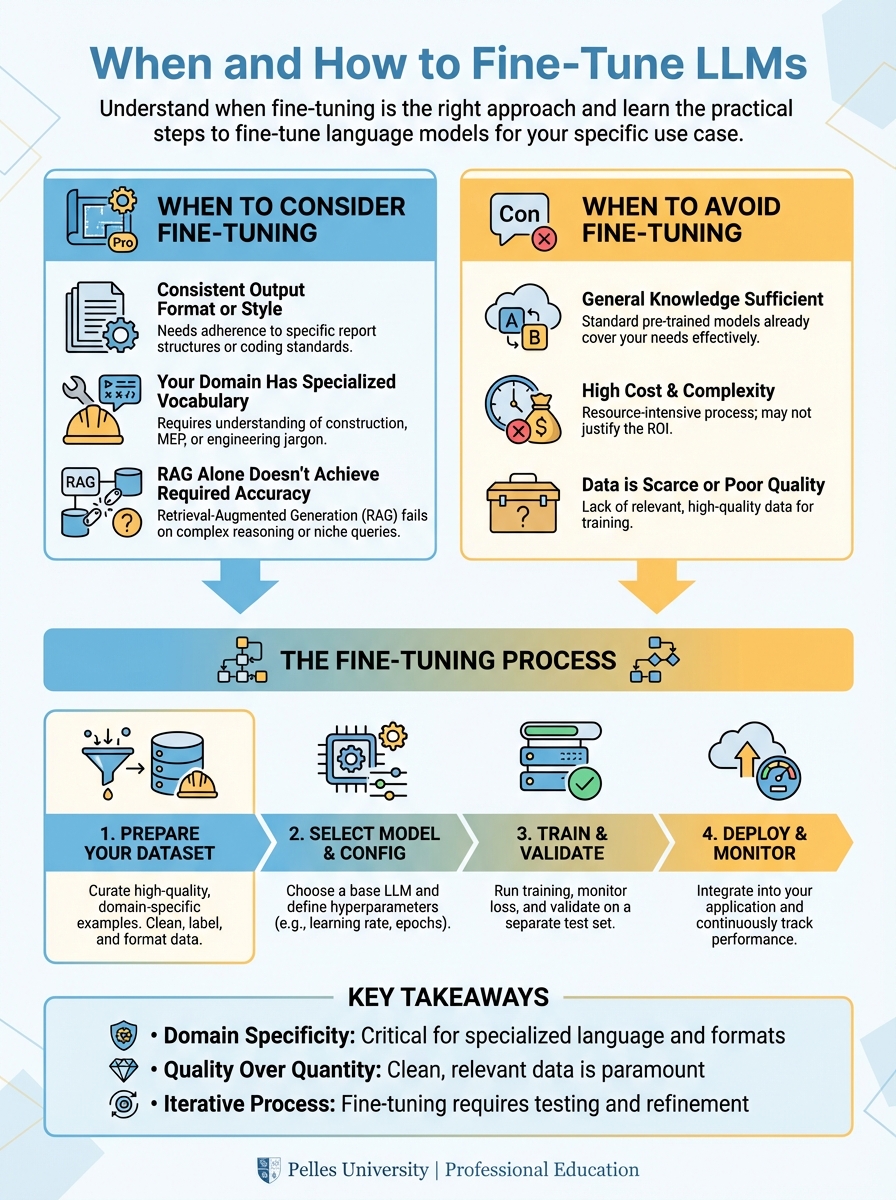
When to Consider Fine-Tuning
Fine-tuning makes sense when:
- You need consistent output format or style
- Your domain has specialized vocabulary
- RAG alone doesn't achieve required accuracy
- You have high-quality training data
When to Avoid Fine-Tuning
Consider alternatives when:
- Your knowledge base changes frequently (use RAG instead)
- You lack sufficient training data
- You need to cite sources (use RAG)
- Prompt engineering achieves acceptable results
The Fine-Tuning Process
1. Prepare Your Dataset
The quality of your fine-tuned model depends entirely on your data:
{
"messages": [
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "What is our return policy?"},
{"role": "assistant", "content": "Our return policy allows..."}
]
}
2. Choose Your Base Model
Consider:
- Task requirements (reasoning, generation, classification)
- Context length needs
- Cost constraints
- Deployment requirements
3. Configure Training
Key hyperparameters:
- Epochs: 2-4 typically sufficient
- Learning rate: Start with 1e-5
- Batch size: Based on memory constraints
4. Evaluate Results
Use held-out test data to measure:
- Task-specific accuracy
- Response quality
- Latency impact
Best Practices
- Start with prompting: Exhaust prompt engineering first
- Quality over quantity: 100 great examples beat 10,000 mediocre ones
- Diverse examples: Cover edge cases in training data
- Version control: Track datasets and model versions
- Monitor drift: Performance can degrade over time
Cost Considerations
Fine-tuning costs include:
- Training compute
- Inference (often more expensive than base models)
- Data preparation time
- Ongoing maintenance
Conclusion
Fine-tuning is a powerful tool but not always the best solution. Carefully evaluate your requirements and consider simpler approaches like prompt engineering or RAG before investing in fine-tuning.